So I’d guess about a year ago now, you were sitting in one of my GLM lectures. Maybe you were paying attention. Maybe you weren’t. If you weren’t you wouldn’t have been alone - fair enough. Even if you were, my guess is that you’ve probably forgotten. Again - fair enough. The bad news is that the methods you’re going to be using for your thesis build on those GLMs.
The good news is that (technically) everything we are going to do in this tutorial series is built on top of what you already know, even if it’s buried somewhere in your brain. The robust design mark-recapture model, which is a crap name tbh, is in its bones just a collection of GLMs talking to each other. So before we get anywhere near that, it is worth making sure the foundations are solid.
This page is not going to teach you anything new. It is going to remind you of what we previously went through, but with a bit more attention paid to what a GLM is actually doing, which I suspect got lost somewhere between the lecture and the exam - fair enough.
What is a GLM doing?
At its core, a GLM is estimating a parameter from data.
A parameter is a just a number. But it’s a number that describes something about the world. The average height of adult humans is a parameter. The probability that a flipped coin lands on heads is a parameter. These are fixed, real values that exist whether or not we ever collect data on them.
The problem is that we can never actually know these values (unless you can speak to a god of your choosing). For the rest of us mortals, we can only estimate them from data. That is the entire job of statistics, and it’s what GLMs (and pretty much all other forms of stats) do.
A concrete example
Let’s say I want to know the probability that a particular species of fish is present in a lake. I survey 20 lakes and record whether the fish species is there or not.
Each row is a lake. fish is 1 if I detected the fish, and 0 if I didn’t. Pretty simple.
Now, I want to know: what is the probability that any given lake contains fish?
I could just take the mean of the fish column:
Code
mean(lakes$fish)
[1] 0.6
60% of the lakes have fish in them. Riveting stuff, I know. Fish, eh? Whoa.
And honestly, for this simple case, 60% is a totally reasonable estimate - no need for any statistical models. But the moment I want to ask why some lakes have fish and others don’t, or the moment I want to figure out how uncertain that 60% is, I need a model.
So here is my model (hint: it’s a GLM):
\[y_i \sim Bernoulli(p_i) \\\]
\[logit(p_i) = \beta_0\]
where:
\(y\) is our observation (fish present or absent in lake \(i\))
\(i\) is an index for which lake we are talking about (e.g. is this the first lake, or the 20th?)
\(\sim\) means “is generated according to”
\(Bernoulli\) is a distribution that produces only 1 or 0
\(p\) is the probability of detecting fish.
\(logit\) is a link function. It is a small piece of maths that keeps \(p\) between 0 and 1, because probabilities cannot be negative or greater than 1. Specifically, \(logit(p) = log\left(\frac{p}{1-p}\right)\)
\(\beta_0\) is the intercept and is the only parameter in the model. Because there are no other covariates in this model, \(\beta_0\) estimates the average probability of detecting fish (on the logit scale).
If you want an explainer of what the logit link function is, check out this old COVID era video:
Let’s fit the GLM (note that fish ~ 1 is just how you specify a model without any covariates in R):
Code
mod <-glm(fish ~1,data = lakes,family = binomial)summary(mod)
Call:
glm(formula = fish ~ 1, family = binomial, data = lakes)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.4055 0.4564 0.888 0.374
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 26.92 on 19 degrees of freedom
Residual deviance: 26.92 on 19 degrees of freedom
AIC: 28.92
Number of Fisher Scoring iterations: 4
The estimate for (Intercept) (i.e. \(\beta_0\)) is on the logit scale. To convert it back to a probability that a human can understand, we use the R function plogis():
Code
plogis(coef(mod))
(Intercept)
0.6
So the model estimates roughly a 60% chance of fish being present in any given lake. Given we simulated the data with a true probability of 60% (you can check in the code above), that’s bang on.
Why bother with a GLM at all?
If we get the same answer using either a GLM or mean(lakes$fish), why bother with the GLM?
Two reasons.
First, mean() breaks the moment you want to include covariates. If you want to ask “how does lake depth affect the probability that fish are present?”, you cannot do that with a mean. You need a model.
Second, a GLM gives you uncertainty. Not just a point estimate, like 60%, but a sense of how confident you should be in that estimate. Look at the Std. Error in the summary output, and look at the 95% confidence intervals:
Code
plogis(confint(mod))
2.5 % 97.5 %
0.3829268 0.7928941
The model is not just saying “60%”. It is saying “somewhere between roughly 38% and 79%, and our best guess is 60%”. That range is information. Ignoring it is how you end up overconfident (cough machine learning cough).
Adding a covariate
Let’s make things a bit more realistic. Given my love and expertise in… fish… I know fish are more likely to be present in deeper lakes. In the code below I’ll simulate some depth data, say fish presence is determined by lake depth and refit the model.
Call:
glm(formula = fish ~ depth, family = binomial, data = lakes)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.3702 1.2965 -0.286 0.775
depth 0.3037 0.2545 1.193 0.233
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 22.493 on 19 degrees of freedom
Residual deviance: 20.943 on 18 degrees of freedom
AIC: 24.943
Number of Fisher Scoring iterations: 4
Now we have two parameters: \(\beta_0\) (the intercept) and \(\beta_1\) (the effect of depth). Our model is now:
\[y_i \sim Bernoulli(p_i) \\\]
\[logit(p_i) = \beta_0 + \beta_1 \times Depth_i\]
The interpretation of \(\beta_1\) on the logit scale is a bit tricky to be honest. It makes everyone’s lives easier if we just visualise the predicted relationship:
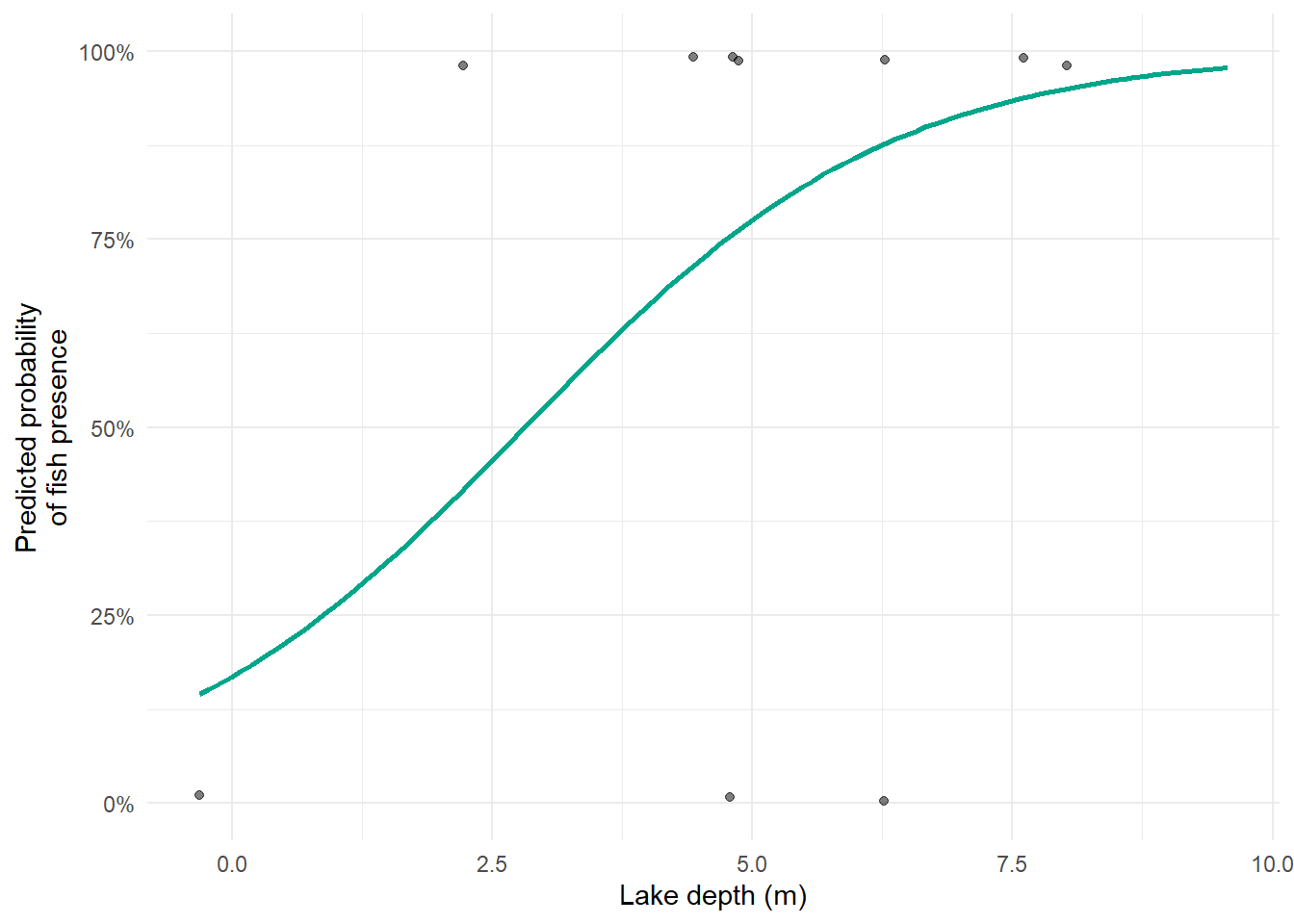
The green line is our model’s prediction. Deeper lakes are estimated to have a higher probability of containing fish, which is what we put into the simulation. The model has recovered the pattern from the data.
We could add 95% confidence intervals to the figure (I should but am being lazy), but importantly we learn more than just 60% of lakes have our fish species in them (when we just calculate the average); we learn that deeper lakes are more likely to have the species present, with shallow lakes having a ca. 12% chance of fish being there, all the way up to 10 m deep lakes being virtually guaranteed to have them with almost 100% chance of the fish being present.
Now try adjusting the two model parameters yourself. The intercept (\(\beta_0\)) shifts the curve left or right along the depth axis, more negative means you need deeper lakes before there is a decent chance of fish. The slope (\(\beta_1\)) controls how steeply probability rises with depth, a larger value means a sharper transition. Notice that no matter what values you choose, the predicted probability always stays between 0 and 1. That is the logit link doing its job. The defaults are set to the true values used to simulate the data above.
The thing I really want you to take away from this page
A GLM estimates a parameter from data. A parameter is just a probability, a rate, a mean, or some other value that describes something about the world that we cannot observe directly ourselves. The GLM gives us a decent guess at that parameter, plus some honest accounting of how uncertain that guess is.
Everything in mark-recapture, and specifically everything in the robust design, follows this exact logic. We’ll just have more parameters to estimate and more models that get fit (at the same time). In doing so, we’ll get some estimates for survival probability, detection probability, population size and a bunch of other ones. None of these are things you will ever be able to observe yourself (how to you “see” survival?). But all of them are things we estimate from data, using models that are, at their core, just GLMs.
The complexity of what is coming is not in the mathematics; though granted the equations look crazy at first. It is in the biology that each parameter is trying to represent, and in making sure we have set the model up in a way that lets us estimate each one without getting them confused with each other.
Quick recap
A GLM estimates parameters (probabilities, means, rates) from data
It uses a link function (like logit) to keep predictions on a sensible scale
It gives you a point estimate and uncertainty
Adding covariates lets you ask why a parameter varies across observations
The plogis() function converts logit-scale estimates back to probabilities
If any of that felt shaky, now is a good time to ask me (I’m genuinely happy to answer questions, even if you feel you should know the answer already). The rest of the tutorial series assumes this is solid.