The Lincoln-Petersen estimator gives us population size \(N\), but only under closure. The population cannot change between your two sampling occasions. That assumption is fine over a day or two. Over weeks or months it becomes fiction.
The Cormack-Jolly-Seber model gives us apparent survival \(\phi\), but it requires the population to be open. Animals can die between occasions, which is precisely what we are trying to estimate. In exchange for that realism, CJS conditions on marked individuals only and cannot estimate \(N\) at all.
So we have two models. One estimates \(N\) but cannot handle survival. The other estimates survival but cannot estimate \(N\). What we actually want is both, from the same study, at the same time.
This is not a minor inconvenience. For most real conservation questions you need both. How many individuals are there and are they surviving well enough to maintain that number? Neither question makes much sense without the other.
The robust design, introduced by Kenneth Pollock in 1982, resolves this tension with an idea that is almost frustratingly simple once you see it.
The key insight: two time scales
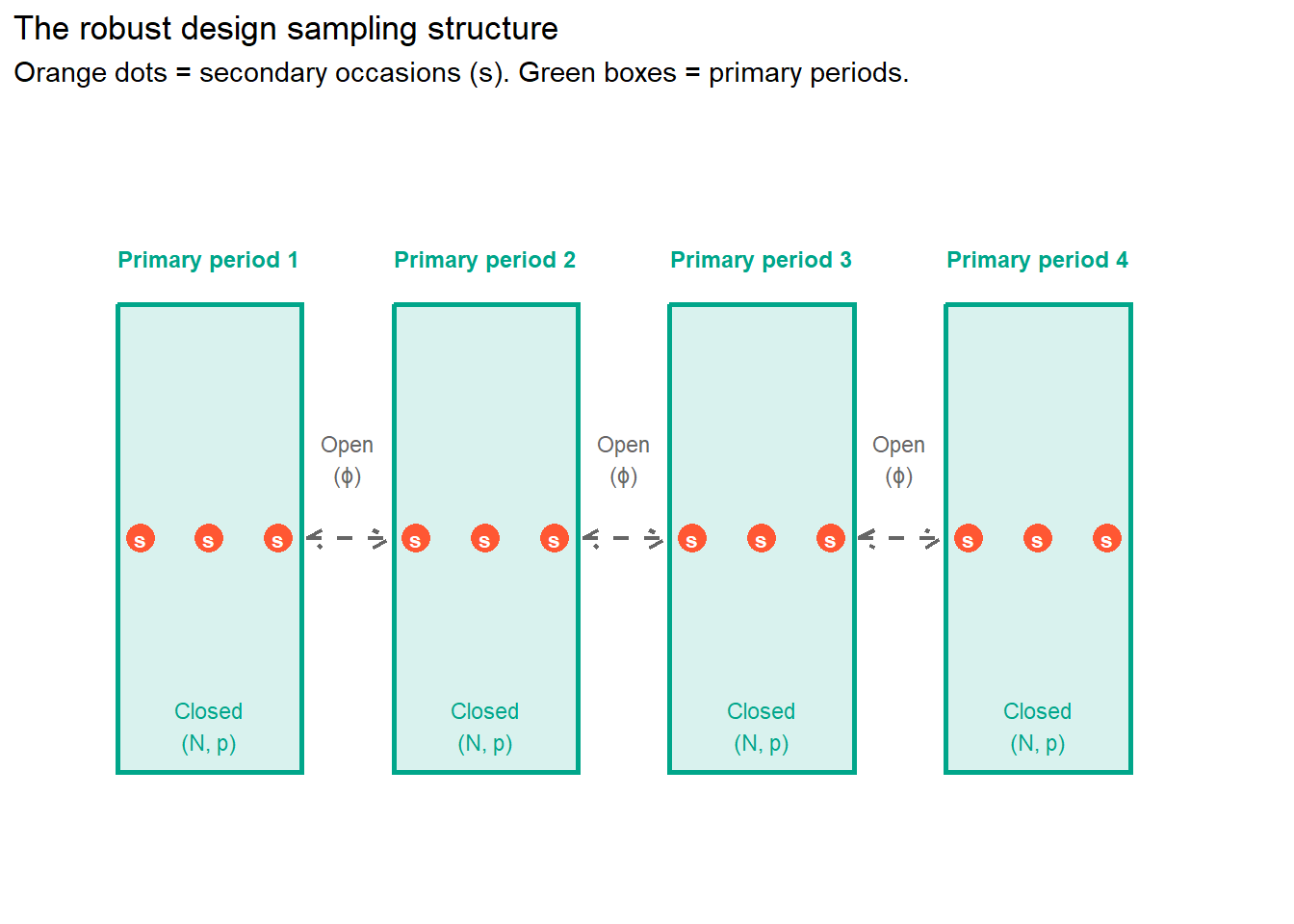
The reason LP and CJS are in conflict is that they need opposite things from the population. LP needs closure. CJS needs openness. The robust design gives each of them what they need by operating at two different time scales simultaneously.
The primary periods are separated by long enough gaps that the population can change between them. Animals can die. Animals can be recruited. This is the open part, handled by CJS-style logic, and it gives us \(\phi\).
The secondary occasions are the repeated sampling events within each primary period, conducted close enough together in time that we can reasonably assume the population is closed during that window. No births, no deaths, no permanent movement in or out. This is the closed part, handled by LP-style logic, and it gives us \(N\).
The robust design nests one inside the other. Closure within primary periods. Openness between them. LP and CJS stop being in conflict because they are now operating at different time scales.
That is the entire conceptual insight. Everything else is working out the details.
The data structure
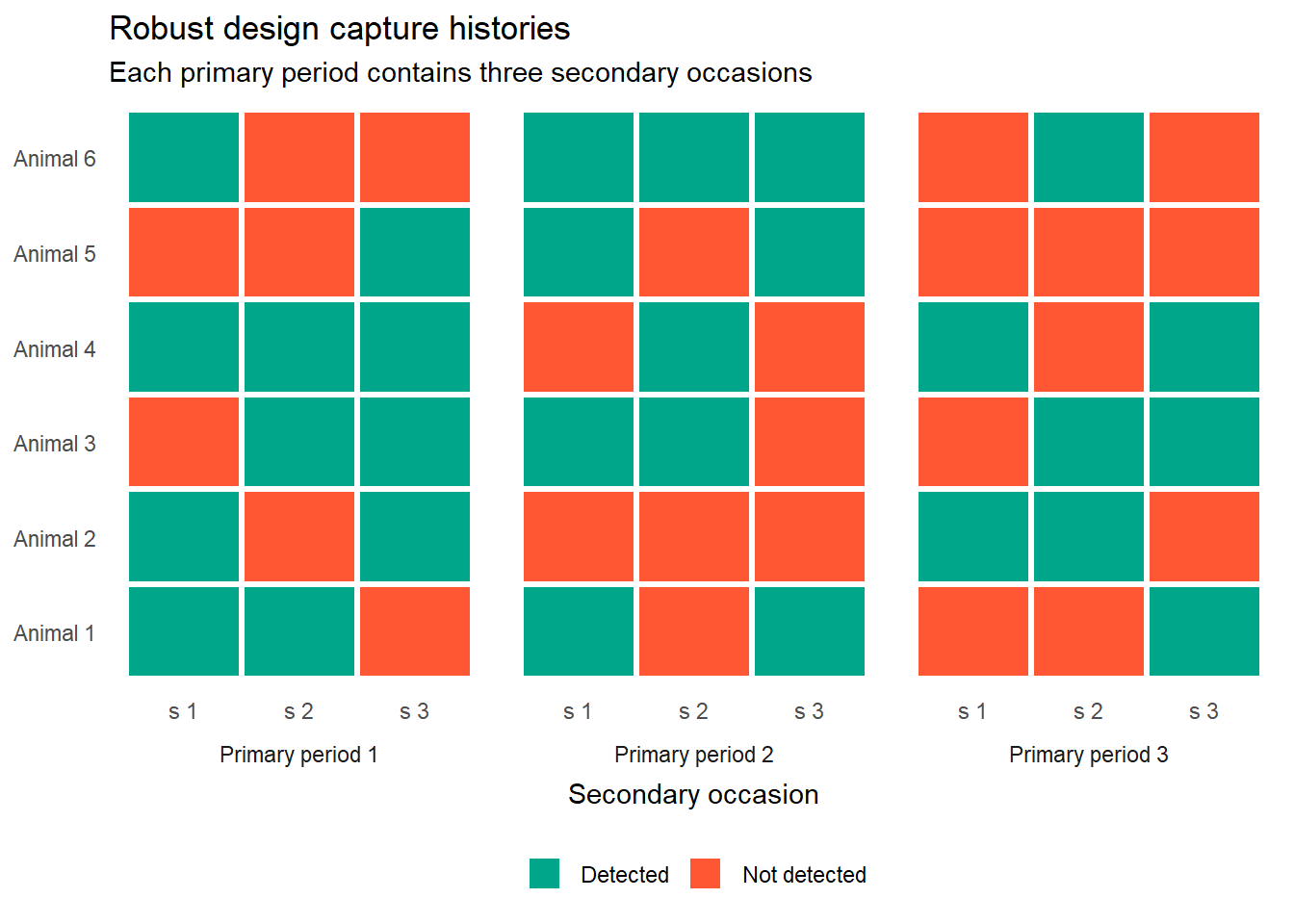
The data structure follows directly from the sampling structure. Each individual now has a capture history that operates at two levels.
At the between-period level, there is a summary detection for each primary period: was the animal detected at least once during that primary period, yes or no? This is the coarse-grained history that feeds the open-population (survival) component of the model.
At the within-period level, there is a detailed detection history across the secondary occasions within each primary period. This fine-grained history feeds the closed-population (abundance and detection) component.
Every red tile carries the same ambiguity as before. But now there are two levels at which that ambiguity operates, and the model deals with each one separately.
Within a primary period, a red tile means the animal was alive and present but not detected. The population is assumed closed so death and emigration are ruled out. The only explanation is imperfect detection.
Between primary periods, a zero summary (never detected across any secondary occasion in a primary period) could mean the animal died before that period, or that it was alive but never detected across any of the secondary occasions. The open-population component of the model handles that ambiguity, just as CJS did.
Building the likelihood
The robust design likelihood separates cleanly into two parts that are estimated together but can be understood separately. We will build each one up in turn.
Part 1: Within primary periods (closed population)
Within each primary period, the population is closed. We have repeated secondary occasions and we want to estimate two things: detection probability \(p\) and population size \(N_t\) for that period.
This is essentially a closed-population mark-recapture model. The simplest version, sometimes called \(M_0\), assumes every individual has the same detection probability \(p\) on every secondary occasion. The probability of an individual’s within-period detection history \(\mathbf{x}_{it} = (x_{it1}, x_{it2}, \ldots, x_{its})\) across \(s\) secondary occasions, given the animal is present, is:
This is just a Bernoulli product. For each secondary occasion, the animal was either detected (\(x = 1\), probability \(p\)) or not (\(x = 0\), probability \(1-p\)).
The probability of not being detected at all during a primary period, across all \(s\) secondary occasions, is:
\[1 - \tilde{p}_t = (1-p)^s\]
So the probability of being detected at least once during primary period \(t\) is:
\[\tilde{p}_t = 1 - (1-p)^s\]
This \(\tilde{p}_t\) is the effective detection probability for the whole primary period. It is the probability that links the within-period model to the between-period model. Notice that even if \(p\) is modest on any single occasion, \(\tilde{p}_t\) can be quite high if you have enough secondary occasions. This is one of the practical benefits of repeated sampling within a period.
To estimate \(N_t\), we use a Huggins-style conditional likelihood (which you don’t need to remember). The important thing is that rather than estimating \(N_t\) directly in the likelihood, we condition on the animals that were detected at least once, estimate \(p\) from their detection histories, and then derive (meaning “figure out”) \(\hat{N}_t\) afterwards as:
\[\hat{N}_t = \frac{n_t}{\hat{\tilde{p}}_t}\]
where \(n_t\) is the number of distinct individuals caught in primary period \(t\). This is Lincoln-Petersen logic in a more general form: we observed \(n_t\) animals, and we estimated that each had a \(\hat{\tilde{p}}_t\) chance of being detected, so the implied population size is \(n_t\) divided by that probability.
Part 2: Between primary periods (open population)
Between primary periods, the CJS machinery takes over. For each individual, we have a between-period capture history summarised as whether they were detected at all in each primary period (\(\omega_{it} = 1\) if detected in any secondary occasion in period \(t\), 0 otherwise).
The between-period likelihood is exactly the CJS likelihood from the previous page, but with one modification: the detection probability entering the CJS component is not the raw \(p\) from a single occasion but the effective detection probability \(\tilde{p}_t\) from the closed-population component.
\[\Pr(\omega_{it} = 1 \mid \text{alive at } t) = \tilde{p}_t\]
The probability of never being seen again from primary period \(t\) onwards, \(\chi_t\), follows the same recursion as before but now uses \(\tilde{p}_t\) in place of the single-occasion \(p\):
The closed-population component is estimated separately within each primary period and delivers \(\hat{p}_t\) and \(\hat{N}_t\). The open-population component uses \(\tilde{p}_t\) derived from \(\hat{p}_t\) and delivers \(\hat{\phi}_t\). The two parts talk to each other through \(\tilde{p}_t\), which is the bridge between the two time scales.
What we can now estimate
The robust design delivers parameters that neither LP nor CJS could provide alone:
Parameter
Symbol
Source
Population size at each primary period
\(N_t\)
Closed component
Detection probability (single occasion)
\(p\)
Closed component
Effective detection probability (per primary period)
\(\tilde{p}_t\)
Derived from \(p\) and \(s\)
Apparent survival between primary periods
\(\phi_t\)
Open component
Population growth rate
\(\lambda_t = N_{t+1}/N_t\)
Derived from \(N_t\)
\(\lambda_t\) is perhaps the most practically useful derived quantity of all. It tells you directly whether the population is growing, stable, or declining between primary periods, and it is estimated honestly, accounting for imperfect detection at both the secondary occasion level and the primary period level.
A small simulation
Let us simulate a robust design dataset and get a feel for how the parameter estimates behave. We will use six primary periods with three secondary occasions each, and keep everything simple with constant \(\phi\) and \(p\). Six primary periods gives the model five survival intervals to work with, which is enough to estimate \(\phi\) reliably.
Be aware that I’m going to use a package called RMark for the modelling here. I’ll come back to this later on, but just know that it requires another piece of software, called program MARK, to be installed in order to run. You can find it here if you want to download and install it now.
Code
library(RMark)set.seed(1988)N_true <-300# Initial population sizephi_true <-0.80# Survival between primary periodsp_true <-0.40# Detection on each secondary occasionn_primary <-6n_secondary <-3# Effective detection probability per primary periodp_tilde <-1- (1- p_true)^n_secondarycat("True N:", N_true,"\nTrue phi:", phi_true,"\nTrue p (single occasion):", p_true,"\nEffective p per primary period:", round(p_tilde, 3))
True N: 300
True phi: 0.8
True p (single occasion): 0.4
Effective p per primary period: 0.784
Code
# Simulate capture historiessim_robust <-function(N, phi, p, n_prim, n_sec, seed =1988) {set.seed(seed)# True alive state across primary periods alive <-matrix(0, nrow = N, ncol = n_prim) alive[, 1] <-1for (t in2:n_prim) { alive[, t] <-rbinom(N, 1, alive[, t -1] * phi) }# Detection history: N x (n_prim * n_sec) det <-matrix(0, nrow = N, ncol = n_prim * n_sec)for (t in1:n_prim) {for (s in1:n_sec) { col <- (t -1) * n_sec + s det[, col] <-rbinom(N, 1, alive[, t] * p) } }# Keep only animals detected at least once det[rowSums(det) >0, ]}ch_data <-sim_robust(N_true, phi_true, p_true, n_primary, n_secondary)ch_strings <-apply(ch_data, 1, paste, collapse ="")rd_df <-data.frame(ch = ch_strings, stringsAsFactors =FALSE)cat("Number of individuals detected at least once:", nrow(rd_df), "\n")
The estimates should land reasonably close to the true values. They will not be exact because we are working with a simulated sample, but the true values should sit comfortably within the confidence intervals.
What is still missing
The model above fixes temporary emigration to zero, which is a simplification we have made deliberately. In reality, animals may temporarily leave your study area between primary periods and return later. They are not dead and not permanently gone, but during their absence they cannot be detected, which creates yet another flavour of ambiguous non-detection.
This is temporary emigration, captured by the parameters \(\gamma'\) and \(\gamma''\) (gamma prime and gamma double prime) that we have quietly set aside here. It is the subject of the next page.
For now, the important thing is that you have the core structure. Closure within primary periods gives you \(N_t\) and \(p\). Openness between primary periods gives you \(\phi\). The two time scales work together through \(\tilde{p}_t\). That structure is the robust design.